It is free to reuse all content from here,
as long as you quote the source of the information:
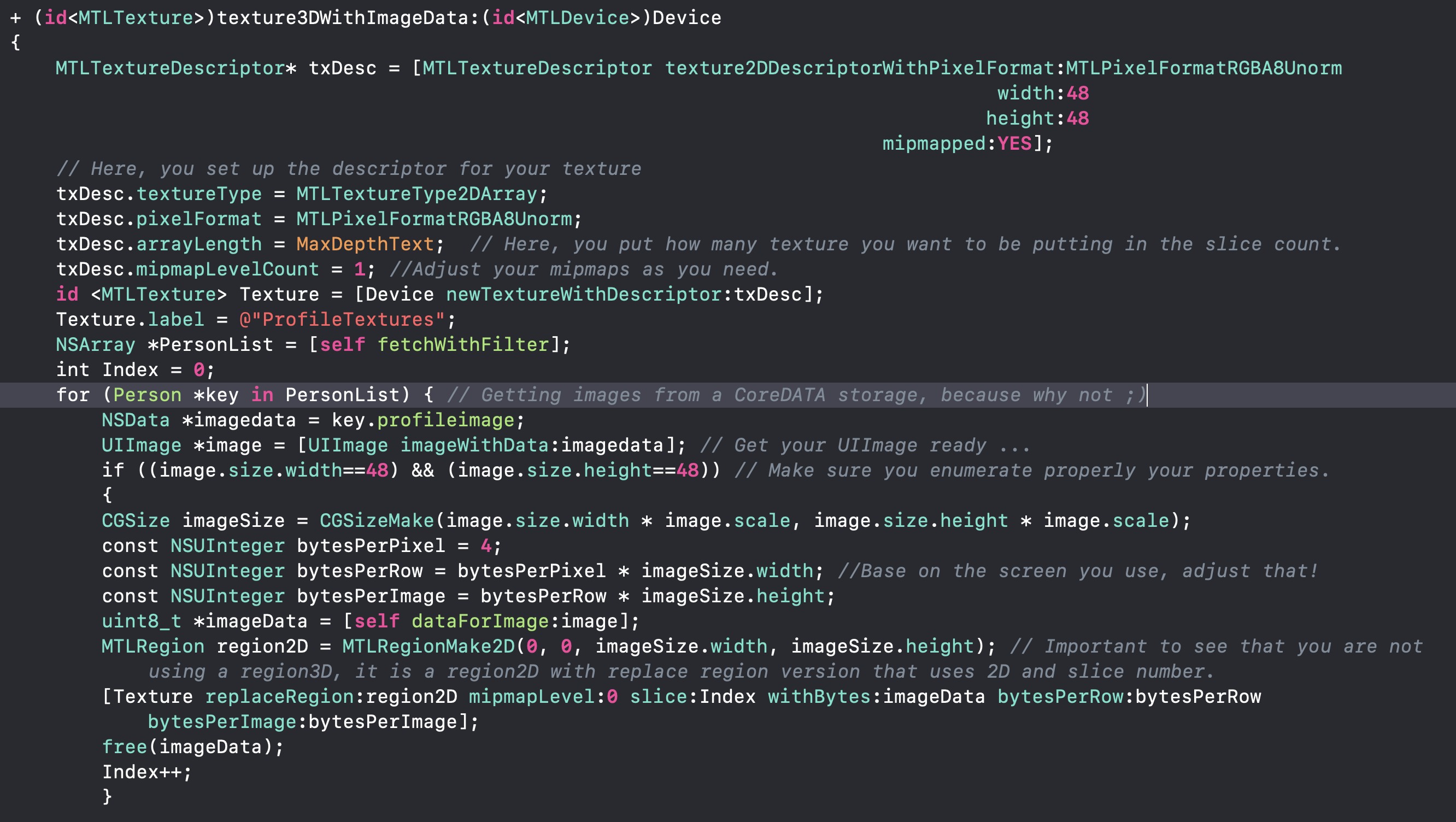
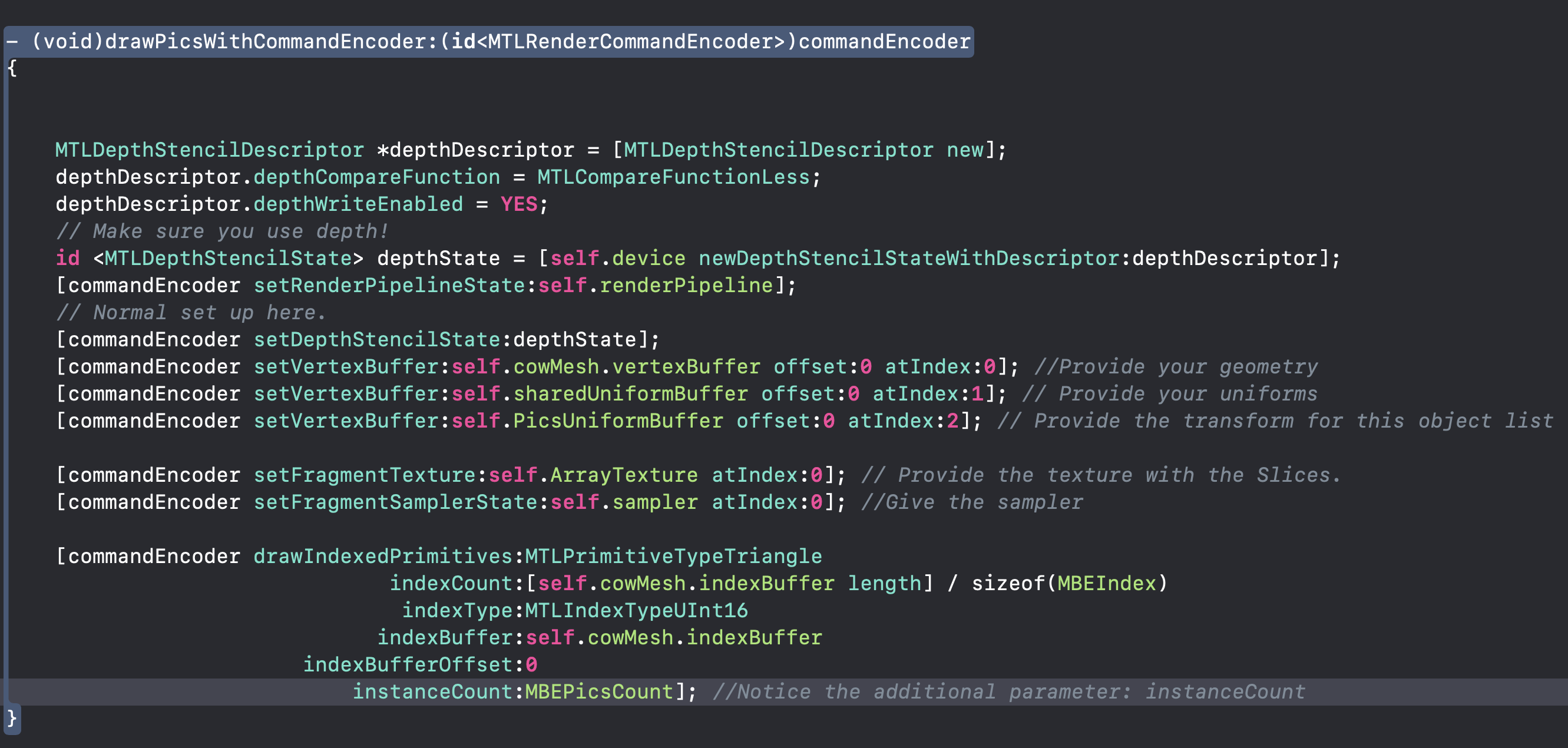
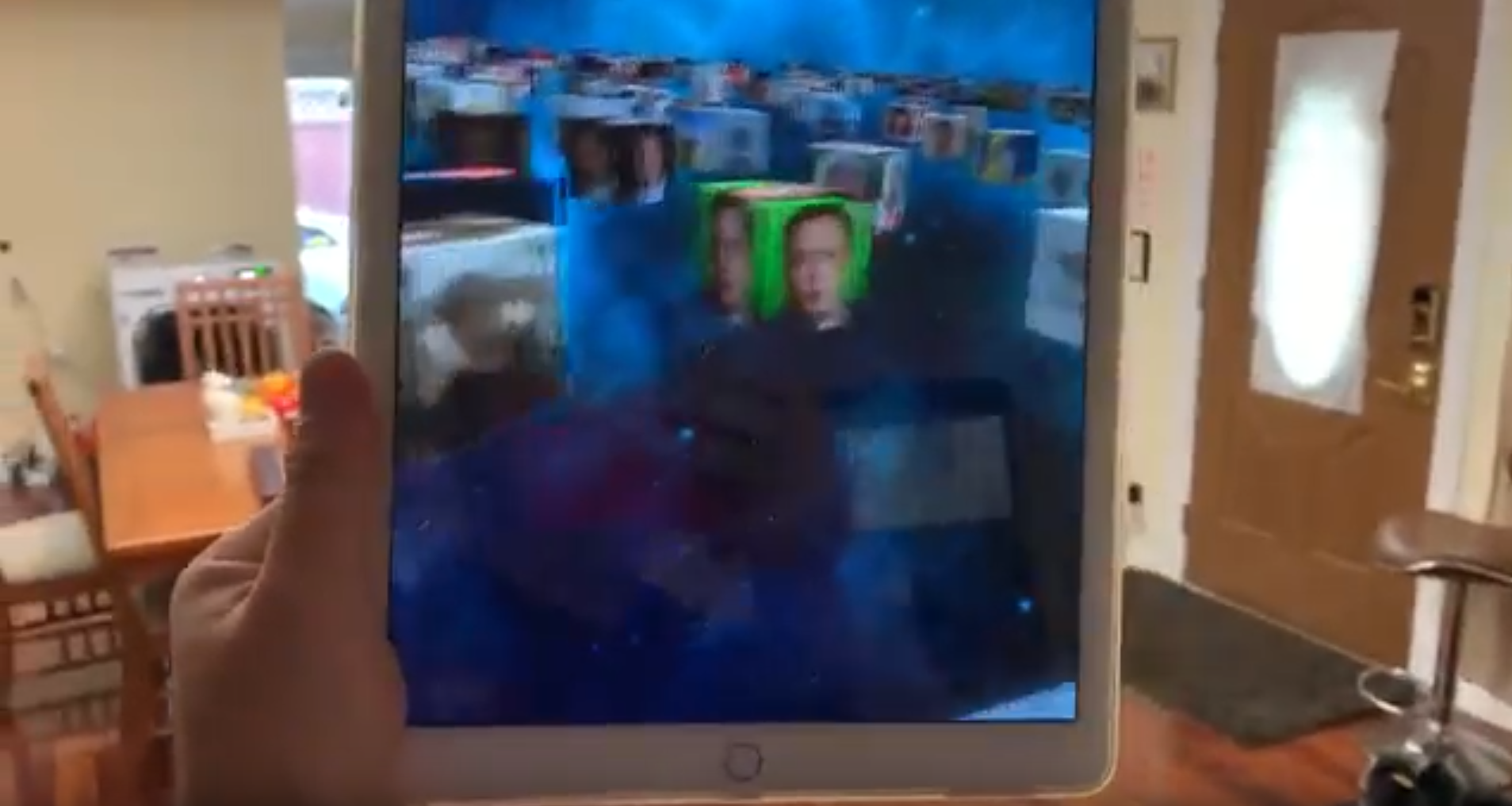
umangnify.com So, I was out to code @humangnify and work for my new employer. Tonight, I started testing seriously the iPhone 11, A13, and there are pretty funny and interesting details coming, so, please stay tuned.
let’s start with the performance of the CoreML engines
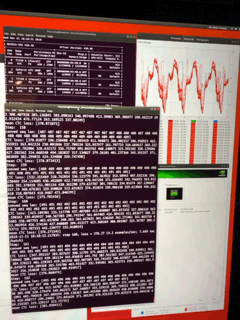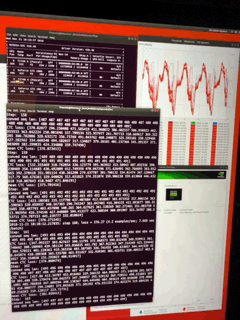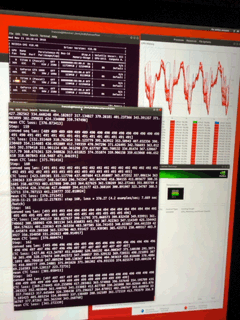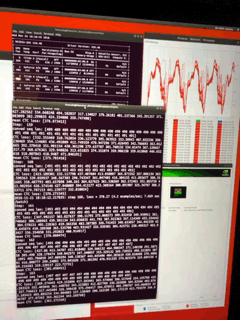
On iPhone XS Max
http://umangnify.com iPhone XS Max
InceptionV3 Run Time: 1689ms
Nudity Run Time: 471ms
Resnet50 Run Time:1702ms
Car Recognition Run Time:631ms
CNNEmotions Run Time:10120ms
GoogleNetPlace Run Time:1340ms
GenderNet Run Time: 761ms
TinyYolo Run Time: 879ms
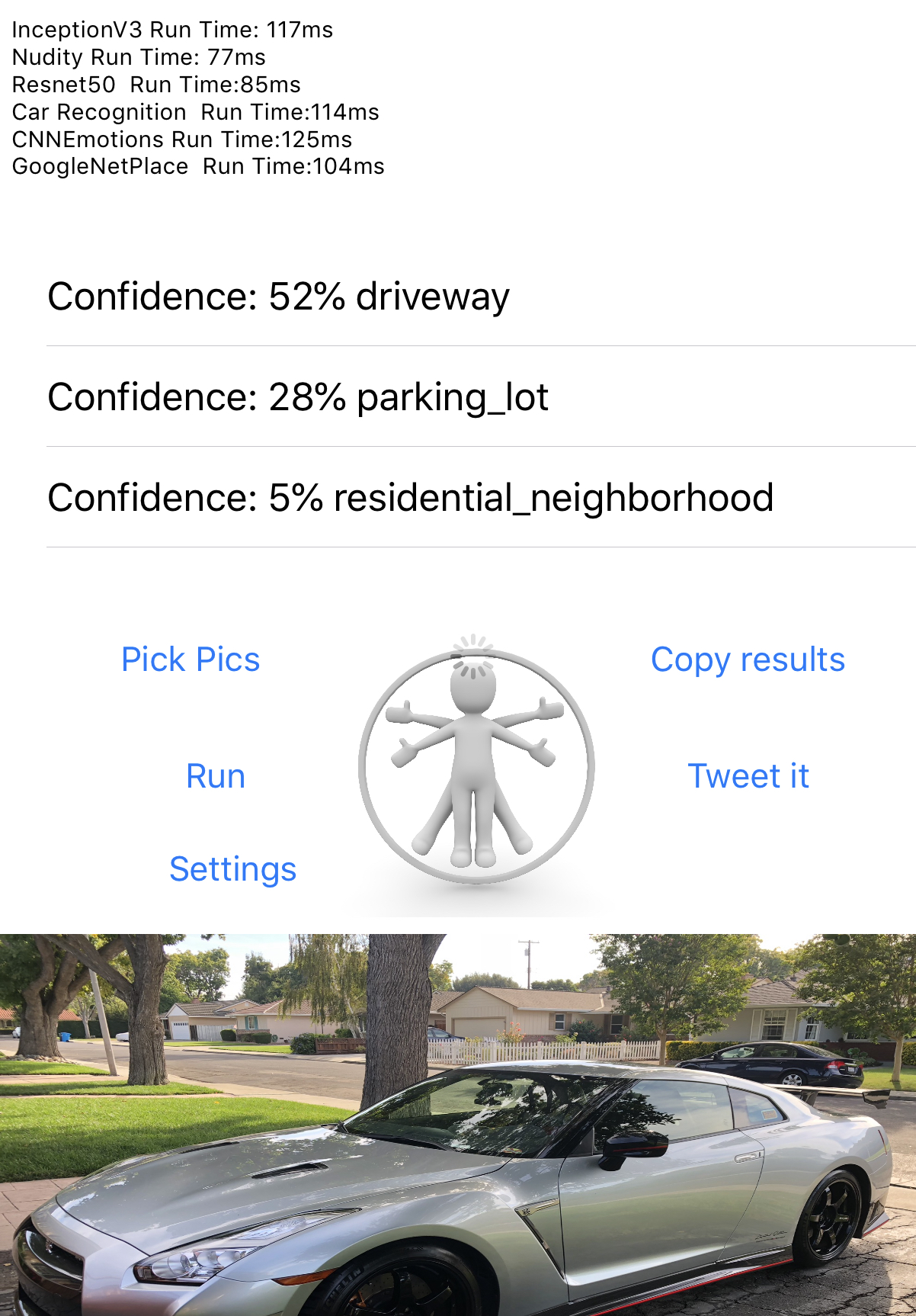
InceptionV3 Run Time: 132ms
Nudity Run Time: 88ms
Resnet50 Run Time:105ms
Car Recognition Run Time:121ms
CNNEmotions Run Time:131ms
GoogleNetPlace Run Time:107ms
GenderNet Run Time: 72ms
TinyYolo Run Time: 86ms
InceptionV3 Run Time: 147ms
Nudity Run Time: 88ms
Resnet50 Run Time:107ms
Car Recognition Run Time:109ms
CNNEmotions Run Time:129ms
GoogleNetPlace Run Time:111ms
GenderNet Run Time: 87ms
TinyYolo Run Time: 211msNow, the iPhone 11 Max Pro

http://umangnify.com results for iPhone 11 Max Pro
InceptionV3 Run Time: 1529ms
Nudity Run Time: 468ms
Resnet50 Run Time:1139ms
Car Recognition Run Time:525ms
CNNEmotions Run Time:9264ms
GoogleNetPlace Run Time:1333ms
GenderNet Run Time: 767ms
TinyYolo Run Time: 895ms
InceptionV3 Run Time: 96ms
Nudity Run Time: 60ms
Resnet50 Run Time:69ms
Car Recognition Run Time:78ms
CNNEmotions Run Time:94ms
GoogleNetPlace Run Time:68ms
GenderNet Run Time: 52ms
TinyYolo Run Time: 148ms
InceptionV3 Run Time: 83ms
Nudity Run Time: 54ms
Resnet50 Run Time:72ms
Car Recognition Run Time:84ms
CNNEmotions Run Time:104ms
GoogleNetPlace Run Time:87ms
GenderNet Run Time: 53ms
TinyYolo Run Time: 122ms
So, here it is , the speed up of the CoreML is pretty nice.
You can see a nice range of performance improvement into the CoreML engine, when the neural network is large, the CoreML engine seems to be having linear limitation due to memory read.
| Benchmark | iPhone Xs Max | iPhone 11 Max Pro | Speed up |
| InceptionV3 | 147 | 83 | 1.77 |
| Nudity checker | 88 | 54 | 1.63 |
| Resnet50 | 107 | 72 | 1.49 |
| Car Recognition | 109 | 84 | 1.30 |
| CNN Emotions | 129 | 104 | 1.24 |
| GoogleNetPlace | 111 | 87 | 1.28 |
| GenderNet | 87 | 53 | 1.64 |
| TinyYolo | 211 | 112 | 1.88 |
unit is Milliseconds, obviously
When looking at the 1st run, the loading of the inference is as slow on the XS and the iPhone 11 … Apple still does not have a bridge in the architecture to speed up the loading. The processor is still used to feed the information into the neural engine inference.
Optimizing a neuronal architecture is a lot easier than a processor core, I was expecting more speed up than this, especially before it seems that the die space is more than 2X.