That is cool stuff, this network will give the app the speech to text with high accuracy, and the sentiment of the speaker. I hope this is going to help the chatboot to be smarter, by giving it a better sharper input.
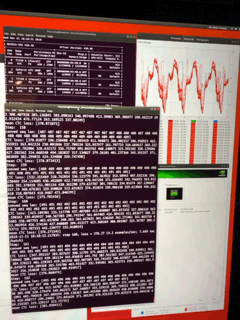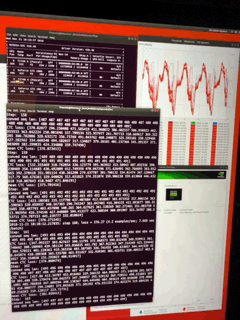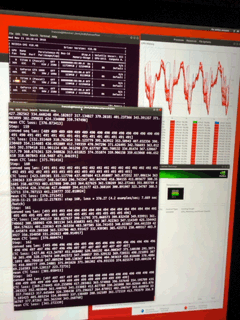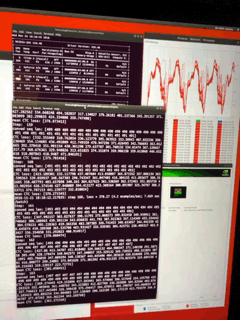
Adding the sentiment detection unbalance my optimization for GPU, right now, it is only using 40% of the 4 GPUs, the 72 cores of the xeon are not pounded either, I ‘ll have to look at this more carefully. If I don’t see the convergence on tensorboard happing fast enough, I may have to stop the run and re-organize the layers, as it is my own alchemy with less layer for the emotion analysis, on a moe of the network. (2 set of FFT analysis as input, one output, with different propagation one common layer in the middle to merge. The size of the training set of RAVDESS is a lot smaller than the input of deepspeech, I never did that kind of mix like this, curious to see what happens.